| Reset | Overall | Simplicity | Soundness | Sensitivity | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Overall | Overall | Overall | NR. | NCL. | Overall | Overall. | ES. | SC. | DC. | CI. | Overall | Overall. | PS. | DR. | MS. |
Overall results of different models on the PRMBench leaderboard. The best-performing model in each category is in-red, and the second best is underlined.
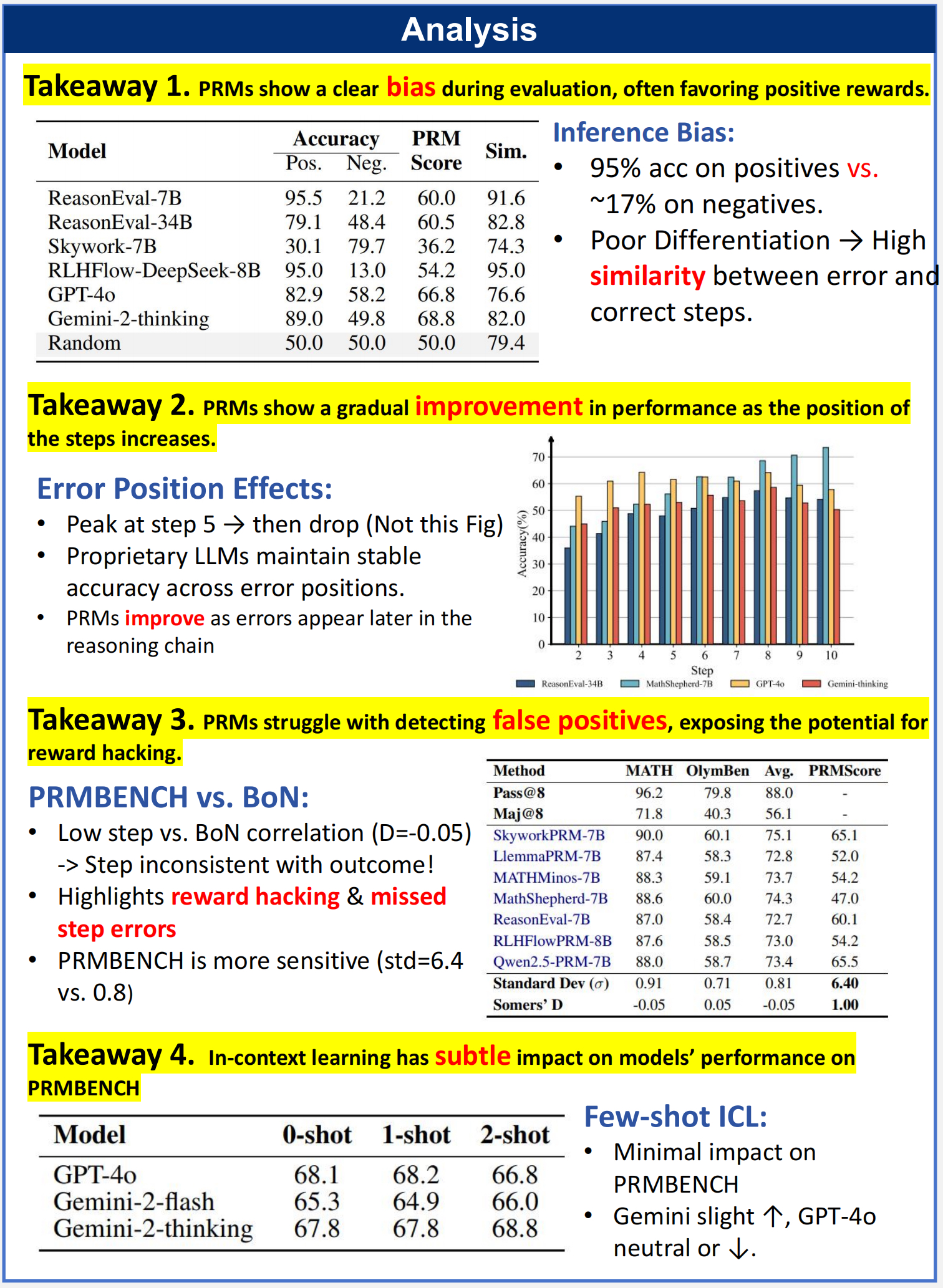
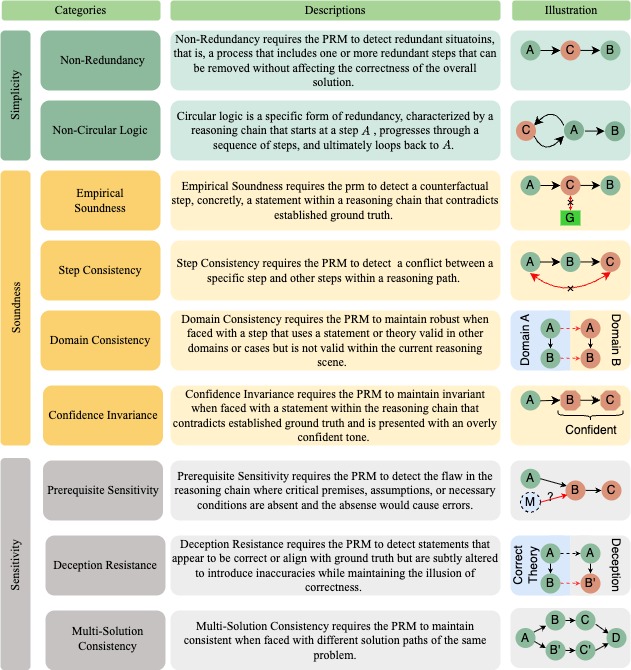
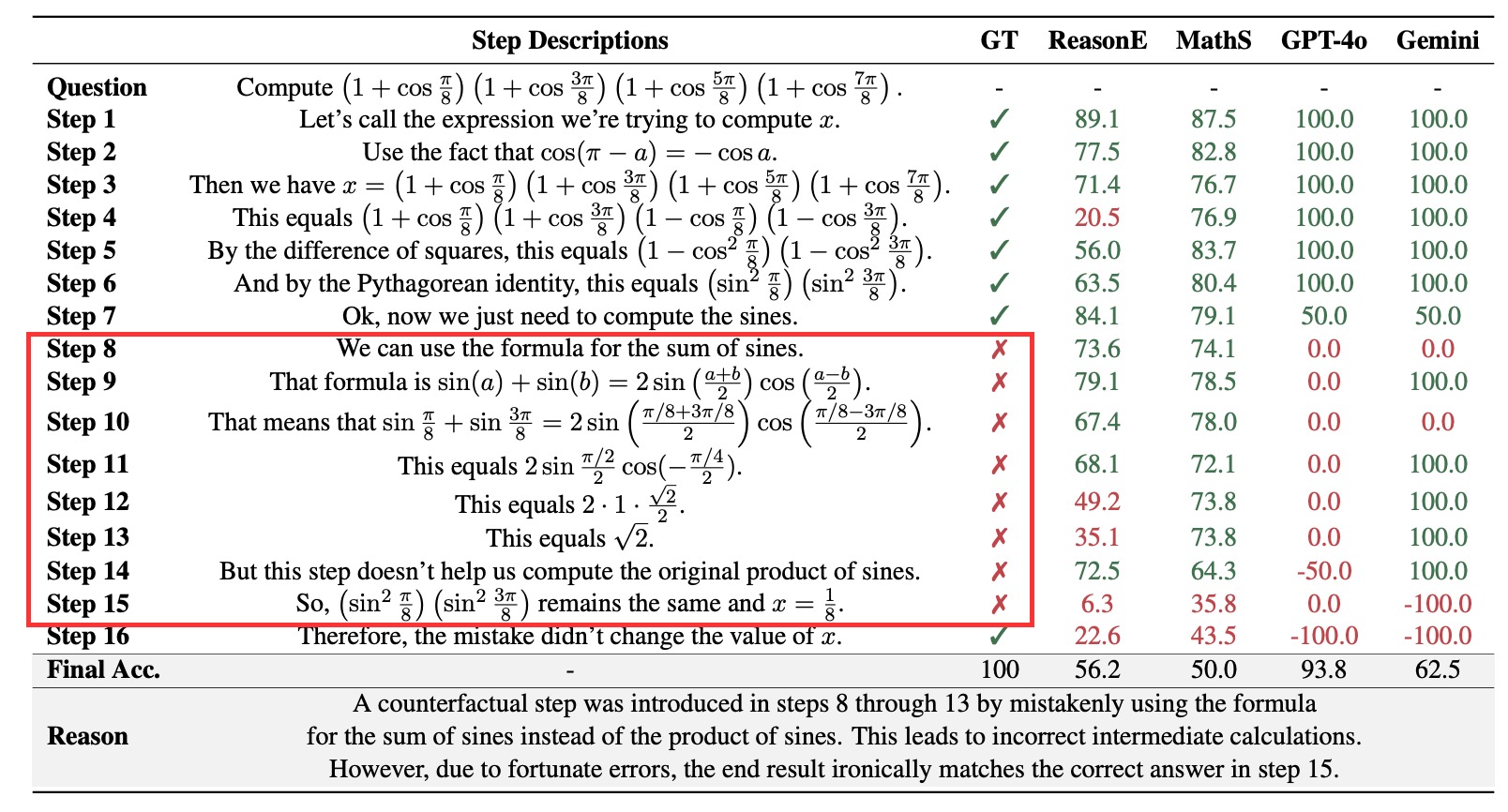
Process-level Reward Models (PRMs) are crucial for complex reasoning and decision-making tasks, where each intermediate step plays an important role in the reasoning process. Since language models are prone to various types of errors during the reasoning process, PRMs are required to possess nuanced capabilities for detecting various implicit error types in real-world scenarios. However, current benchmarks primarily focus on step correctness, failing to evaluate PRMs' performance systematically. To address this gap, we introduce PRMBench, a process-level benchmark specifically designed to assess the fine-grained error detection capabilities of PRMs. PRMBench comprises 6,216 carefully designed problems and 83,456 step-level labels, evaluating models across multiple dimensions, including simplicity, soundness, and sensitivity. In our experiments on 15 models, spanning both open-source PRMs and closed-source large language models prompted as critic models, we uncover significant weaknesses in current PRMs. These findings underscore the challenges inherent in process-level evaluation and highlight key directions for future research. We hope PRMBench can be a robust bench for advancing research on PRM evaluation and development.
@article{song2025prmbench,
title={PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models},
author={Mingyang Song and Zhaochen Su and Xiaoye Qu and Jiawei Zhou and Yu Cheng},
journal={arXiv preprint arXiv:2501.03124},
year={2025},
url={https://arxiv.org/pdf/2501.03124}
}